DuplicateFF v1.0.0
Professional duplicate file finder with a progressive hashing pipeline for terabyte-scale scanning. PowerShell WPF with Catppuccin Mocha dark theme.
Features
- Progressive Hashing Pipeline - 5-stage elimination (size grouping, prefix hash, suffix hash, full SHA256) minimizes disk I/O
- Reference Folders - Mark folders as protected; duplicates will never be selected from these locations
- File Type Filters - Images, Videos, Audio, Documents, or All Files
- Image Preview - Inline preview panel for visual verification before deletion
- Auto-Select Rules - Keep Newest, Oldest, From Reference Folders, Largest, or Shortest Path
- Safe Deletion - Move to Recycle Bin (default), Permanent Delete, or Replace with Hardlinks
- CSV Export - Full results export with hash values, groups, and file metadata
- Async Scanning - Non-blocking UI with real-time progress and cancellation support
- Dark Theme - Catppuccin Mocha with premium UI styling
Usage
.\DuplicateFF.ps1
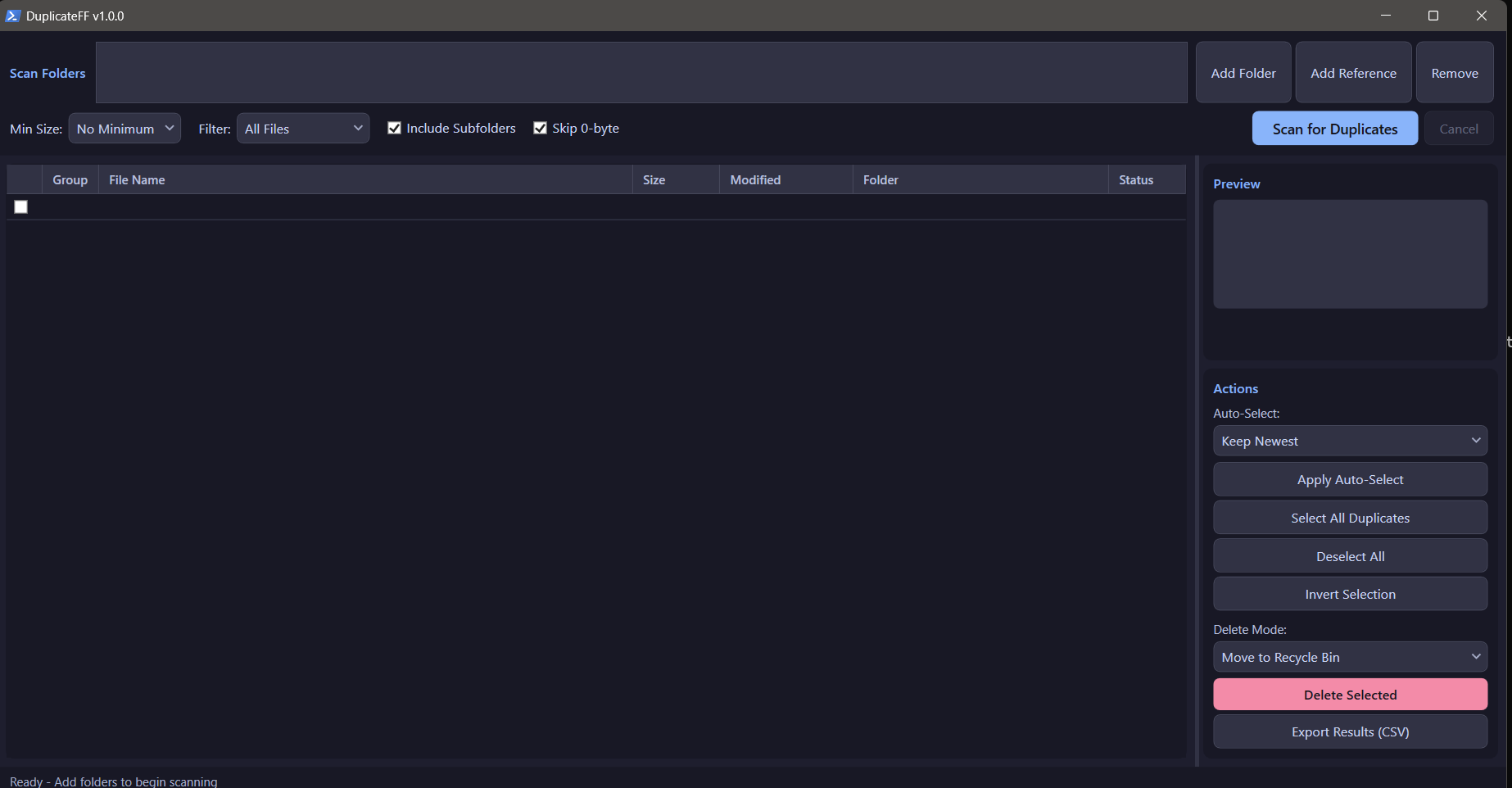
- Click Add Folder to add directories to scan
- Optionally add Reference Folders (protected from deletion)
- Set filters (min size, file type, subfolders)
- Click Scan for Duplicates
- Review results, use auto-select or manual checkbox selection
- Choose delete mode and click Delete Selected
How It Works
The progressive hashing pipeline avoids reading entire files whenever possible:
| Stage | Action | Typical Elimination |
|---|---|---|
| 1 | Enumerate files with filters | N/A |
| 2 | Group by file size | ~70% of files |
| 3 | SHA256 of first 4KB | ~15% more |
| 4 | SHA256 of last 4KB | ~5% more |
| 5 | Full SHA256 hash | Final confirmation |
Only files surviving all stages get fully hashed, making scans fast even on large datasets.
Research
See Building a professional duplicate file finder: A technical guide for the research behind this tool, covering algorithm selection, perceptual hashing for AI upscale detection, and performance architecture.
License
MIT License